




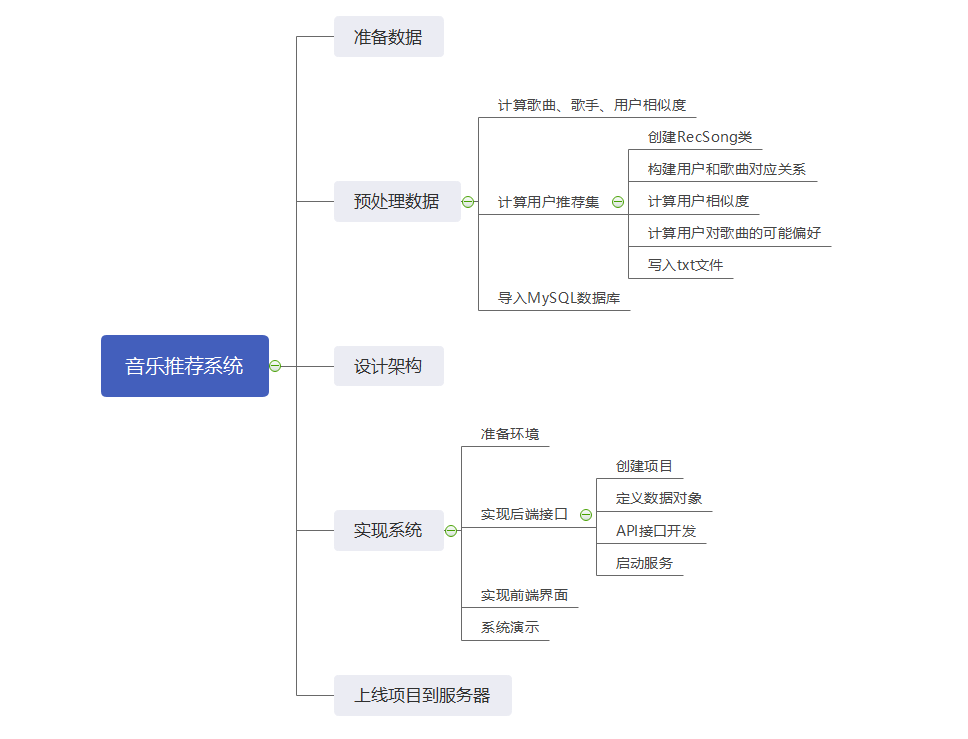
音乐推荐系统
项目访问地址为:http://8.136.103.40:8001/
后台管理系统访问地址为(用户名和密码均为admin):http://8.136.103.40:8000/admin/
1、准备数据
使用的数据来源是网易云音乐上的部分数据,选择了一千多个歌单进行响应的数据获取,包括歌单信息、歌手信息、歌曲信息、用户信息。
数据保存在txt文件中,由于信息中含有大量文本,且文本中包含的符号比较丰富,所以这里采用"|=|"分隔每个字段。样例数据展示如下图所示:

2、预处理数据
爬虫获取的数据需要经过一定的整理和计算才能为系统所使用,所以在系统开始之前先对数据进行预处理。
2.1、计算歌曲、歌手、用户相似度
该部分数据主要是为了产生某个歌单、歌曲、歌手、用户的相似推荐。该部分的计算是基于标签进行的,用户在创建歌单时指定了标签,所以系统认为用户对该标签有偏好,遍历用户创建的所有歌单,会产生用户的标签向量。
例如,系统中有3个标签(日语、嘻哈、沉默),如果用户张三在所有创建的歌单中使用的标签为日语和嘻哈,则用户张三对应的标签向量为[1,1,0],进而根据用户的标签向量计算用户相似度。
计算用户相似度的核心代码如下:
# 计算用户相似度,由于全量用户存储数据量大
# 且无用所以这里只存储了每个用户的相近20个用户,并且要求相似度大于0.8
def getUserSim(self):
sim = dict()
if os.path.exists("./data/user_sim.json"):
sim = json.load(open("./data/user_sim.json","r",encoding="utf-8"))
else:
i = 0
for use1 in self.userTags.keys():
sim[use1] = dict()
for use2 in self.userTags.keys():
if use1 != use2:
j_len = len (self.userTags[use1] & self.userTags[use2] )
if j_len !=0:
result = j_len / len(self.userTags[use1] | self.userTags[use2])
if sim[use1].__len__() < 20 or result > 0.8:
sim[use1][use2] = result
else:
# 找到最小值 并删除
minkey = min(sim[use1], key=sim[use1].get)
del sim[use1][minkey]
i += 1
print(str(i) + "\t" + use1)
json.dump(sim, open("./data/user_sim.json","w",encoding="utf-8"))
print("用户相似度计算完毕!")
return sim
歌手、歌曲的相似度算逻辑与用户相似度计算逻辑相同。用户相似度计算代码对应文件z-others/tools/userSim.py,歌手相似度计算代码对应文件z-others/tools/singSim.py,歌曲相似度计算代码对应文件z-others/tools/songSim.py。
2.2、计算用户推荐集
该部分数据主要是为了产生登录系统的用户在进入歌单、歌曲、歌手、用户模块时,界面右侧的推荐。
该部分的推荐算法包括:基于内容的推荐算法、基于用户和基于物品的协同过滤算法。
基于内容的推荐算法简介:
基于内容的推荐算法,根据用户过去一段时间内喜欢的物品,以及由此推算出来用户偏好,为用户推荐相似物品。其中的“内容”指的是:用户过去一段时间内喜欢的物品,以及由此推算出来的用户偏好。
算法原理----从“构造特征”到“判断用户是否喜欢”
基于内容的推荐原理非常简单:向用户推荐所喜欢的Item的相似Item。其中包含三部:
(1)构造Item的特征
(2)计算Item之间的相似度
(3)评价用户是否喜欢某个Item
1.构造Item的特征
在真实应用场景中,往往会用一些属性来描述Item的特征,这些属性通常分为以下两种:
结构化属性:意义比较名气,其取值固定在某个范围内。
非结构化属性:特征意义相对不太明确,取值没有什么限制,不可以直接使用。
2.计算Item之间的相似度
在确定好Item的特征和用户的偏好模型后,需要计算两个Item间的相似度。根据具体场景,往往需要使用不同的相似度计算方法。
3.判断用户是否喜欢
在推荐算法中评价用户是否喜欢某个Item就是:利用监督学习或非监督学习的方法,来评价用户喜欢那些Item,不喜欢哪些Item,从而根据用户的喜好,为他生成一个偏好模型,进而对未知的Item进行喜好评判
在基于内容的推荐算法中,使用的则是监督学习,利用用户对Item的已知评分和Item所属的类别,学习得到用户对每种类型的偏好程度,然后结合Item的类别特征计算用户对Item的偏好程度。
监督学习(Supervised Learning):利用一组已知类别的样本,调整模型的参数,从而对未知样本进行类别判断或回归计算。
非监督学习(Unsupervised Learning):样本的类别未知,通过模型对未知类别的样本进行分类。
下面详细介绍基于用户的协同过滤为用户产生歌曲推荐,其实现步骤为:
(1)构建用户与歌曲的对应关系
(2)计算用户与用户之间的相似度
(3)为用户推荐相似用户喜欢的歌曲
下面是具体实现过程
1.创建RecSong类
class RecSong:
def __init__(self):
self.playlist_mess_file = "../tomysql/data/pl_mess_all.txt"
self.playlist_song_mess_file = "../tomysql/data/pl_sing_id.txt"
self.song_mess_file = "../tomysql/data/song_mess_all.txt"
在_init_(self)中指定了所使用的的文件
2.构建用户和歌曲对应关系
用户创建了歌单,歌单包含歌曲。当用户把一首歌归档到歌单中时,则认为用户对该首歌曲的评分值为1。如果用户对一首歌曲产生了多次归档行为,则评分值依次加1.
其代码实现如下:
# 加载数据 => 用户对歌曲的对应关系
def load_data(self):
# 所有用户
user_list = list()
# 歌单和歌曲对应关系
playlist_song_dict = dict()
for line in open(self.playlist_song_mess_file, "r", encoding="utf-8"):
# 歌单 \t 歌曲s
playlist_id, song_ids = line.strip().split("\t")
playlist_song_dict.setdefault(playlist_id, list())
for song_id in song_ids.split(","):
playlist_song_dict[playlist_id].append(song_id)
# print(playlist_sing_dict)
print("歌单和歌曲对应关系!")
# 用户和歌曲对应关系
user_song_dict = dict()
for line in open(self.playlist_mess_file, "r", encoding="utf-8"):
pl_mess_list = line.strip().split(" |=| ")
playlist_id, user_id = pl_mess_list[0], pl_mess_list[1]
if user_id not in user_list:
user_list.append(user_id)
user_song_dict.setdefault(user_id, {})
for song_id in playlist_song_dict[playlist_id]:
user_song_dict[user_id].setdefault(song_id, 0)
user_song_dict[user_id][song_id] += 1
# print(user_song_dict)
print("用户和歌曲对应信息统计完毕 !")
return user_song_dict, user_list
3.计算歌曲的相似度
为用户推荐歌曲采用的是基于用户的协同过滤算法。所以这里需要计算出的是用户相似度。计算用户相似度分为两部:构建倒排表、构建相似度矩阵。其实现代码如下:
# 计算用户之间的相似度
def UserSimilarityBest(self):
"""
计算用户之间的相似度,采用惩罚热门商品和优化算法复杂度的算法
:return: dict
"""
# 得到每个item被哪些user评价过
tags_users = dict()
for user_id, tags in self.user_tags_count_dict.items():
for tag in tags.keys():
tags_users.setdefault(tag,set())
if self.user_tags_count_dict[user_id][tag] > 0:
tags_users[tag].add(user_id)
# 构建倒排表
C = dict()
N = dict()
for tags, users in tags_users.items():
for u in users:
N.setdefault(u,0)
N[u] += 1
C.setdefault(u,{})
for v in users:
C[u].setdefault(v, 0)
if u == v:
continue
C[u][v] += 1 / math.log(1+len(users))
# 构建相似度矩阵
W = dict()
for u, related_users in C.items():
W.setdefault(u,{})
for v, cuv in related_users.items():
if u==v:
continue
W[u].setdefault(v, 0.0)
W[u][v] = cuv / math.sqrt(N[u] * N[v])
return W
4.计算用户对歌曲的可能偏好
遍历用户的所有相似用户,对于相似用户中没有产生过归档行为的歌曲,计算用户对他们的偏好,其实现代码如下:
# 为每个用户推荐歌曲
def recommend_song(self):
# 记录用户对歌手的评分
user_song_score_dict = dict()
if os.path.exists("./data/user_song_prefer.json"):
user_song_score_dict = json.load(open("./data/user_song_prefer.json", "r", encoding="utf-8"))
print("用户对歌手的偏好从文件加载完毕!")
return user_song_score_dict
for user in self.user_song_dict.keys():
print(user)
user_song_score_dict.setdefault(user, {})
# 遍历所有用户
for user_sim in self.user_sim[user].keys():
if user_sim == user:
continue
for song in self.user_song_dict[user_sim].keys():
user_song_score_dict[user].setdefault(song,0.0)
user_song_score_dict[user][song] += self.user_sim[user][user_sim] * self.user_song_dict[user_sim][song]
json.dump(user_song_score_dict, open("./data/user_song_prefer.json", "w", encoding="utf-8"))
print("用户对歌曲的偏好计算完成!")
return user_song_score_dict
5.写入文件
对每个用户的歌曲偏好进行排序,将用户最可能产生归档行为(即最可能产生偏好)的前100首歌曲写入文件,便于导入mysql数据库,供系统使用。其实现代码如下:
# 写入文件
def write_to_file(self):
fw = open("./data/user_song_prefer.txt","a",encoding="utf-8")
for user in self.user_song_score_dict.keys():
sort_user_song_prefer = sorted(self.user_song_score_dict[user].items(), key=lambda one:one[1], reverse=True)
for one in sort_user_song_prefer[:100]:
fw.write(user+','+one[0]+','+str(one[1])+'\n')
fw.close()
print("写入文件完成")
然后在init中增加引用
self.user_song_dict,self.user_list = self.load_data()
self.user_sim = self.UserSimilarityBest()
self.user_song_score_dict = self.recommend_song()
创建main函数,触发计算
if __name__ == "__main__":
rec_song = RecSong()
rec_song.write_to_file()
运行代码,显示信息如下:

user_song_prefer.txt文件中的内容如下:
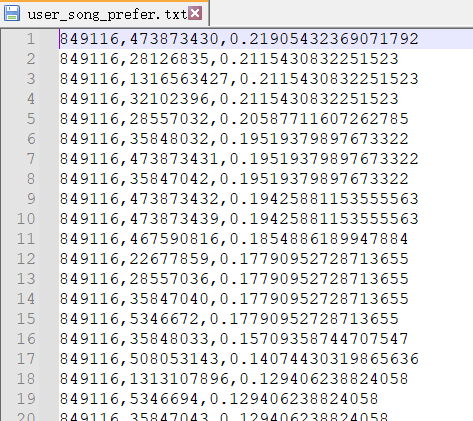
同样,歌手、歌单、用户的推荐结果集也通过类似的计算方式进行计算,其计算代码和文件对应关系为:歌单推荐对应rec_playlist.py,歌手推荐对应rec_sing.py,用户推荐对应rec_user.py,歌曲推荐(就是以上所讲)对应rec_song.py。
2.3、数据导入mysql数据库
准备好基础数据后,需要将数据导入mysql数据库,以供系统使用。这里使用数据导入数据库方式为:python连接mysql数据库进行导入。以歌单信息导入mysql数据库为例。
这里使用的后端框架为python的Django。Django是典型的MVC框架,在数据库的基础上封装了一个model层,通过类与数据表的映射,可以对数据库进行操作。其中将歌单信息导入数据库的代码如下:
# 歌单信息写入数据库 ok
"""
pl_id = models.CharField(blank=False, max_length=64, verbose_name="ID", unique=True)
pl_creator = models.ForeignKey(User, related_name="创建者信息", on_delete=False)
pl_name = models.CharField(blank=False, max_length=64, verbose_name="歌单名字")
pl_create_time = models.DateTimeField(blank=True, verbose_name="创建时间")
pl_update_time = models.DateTimeField(blank=True, verbose_name="更新时间")
pl_songs_num = models.IntegerField(blank=True,verbose_name="包含音乐数")
pl_listen_num = models.IntegerField(blank=True,verbose_name="播放次数")
pl_share_num = models.IntegerField(blank=True,verbose_name="分享次数")
pl_comment_num = models.IntegerField(blank=True,verbose_name="评论次数")
pl_follow_num = models.IntegerField(blank=True,verbose_name="收藏次数")
pl_tags = models.CharField(blank=True, max_length=1000, verbose_name="歌单标签")
pl_img_url = models.CharField(blank=True, max_length=1000, verbose_name="歌单封面")
pl_desc = models.TextField(blank=True, verbose_name="歌单描述")
"""
def playListMessToMysql(self):
i=0
for line in open("./data/pl_mess_all.txt", "r", encoding="utf-8"):
pl_id, pl_creator, pl_name, pl_create_time, pl_update_time, pl_songs_num, pl_listen_num, \
pl_share_num, pl_comment_num, pl_follow_num, pl_tags, pl_img_url, pl_desc = line.split(" |=| ")
try:
user = User.objects.filter(u_id=pl_creator)[0]
except:
user = User.objects.filter(u_id=pl_creator)[0]
pl = PlayList(
pl_id = pl_id,
pl_creator = user,
pl_name = pl_name,
pl_create_time = self.TransFormTime(int(pl_create_time)/1000),
pl_update_time = self.TransFormTime(int(pl_update_time)/1000),
pl_songs_num = int (pl_songs_num),
pl_listen_num = int( pl_listen_num ),
pl_share_num = int( pl_share_num) ,
pl_comment_num = int (pl_comment_num),
pl_follow_num = int(pl_follow_num),
pl_tags = str(pl_tags).replace("[","").replace("]","").replace("\'",""),
pl_img_url = pl_img_url,
pl_desc = pl_desc
)
pl.save()
i+=1
print(i)
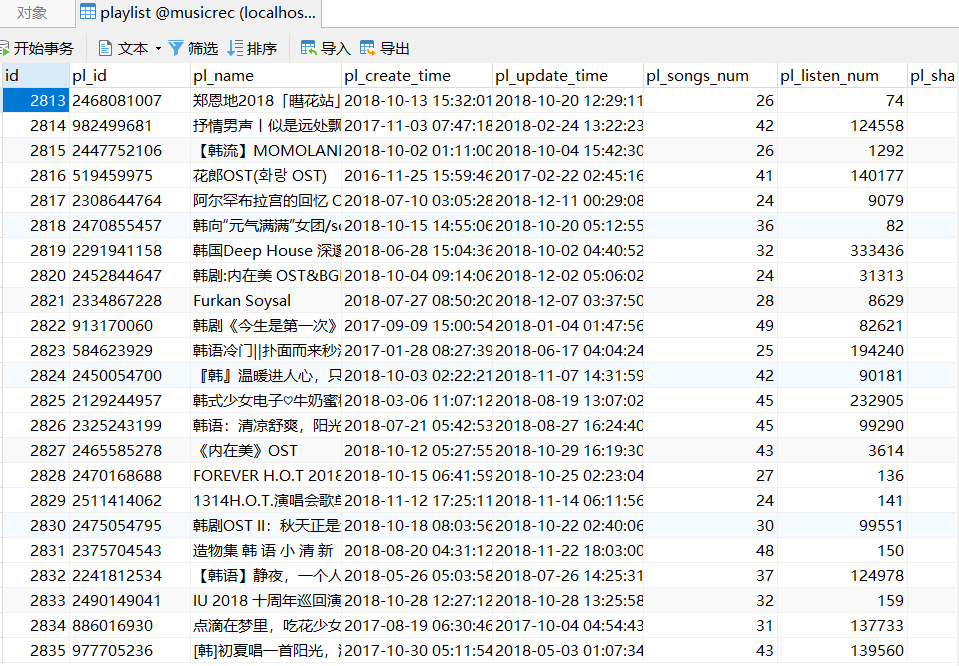
执行完代码后,可以在mysql数据库中看到信息,这里使用navicat连接mysql数据库查看信息,如下图所示:
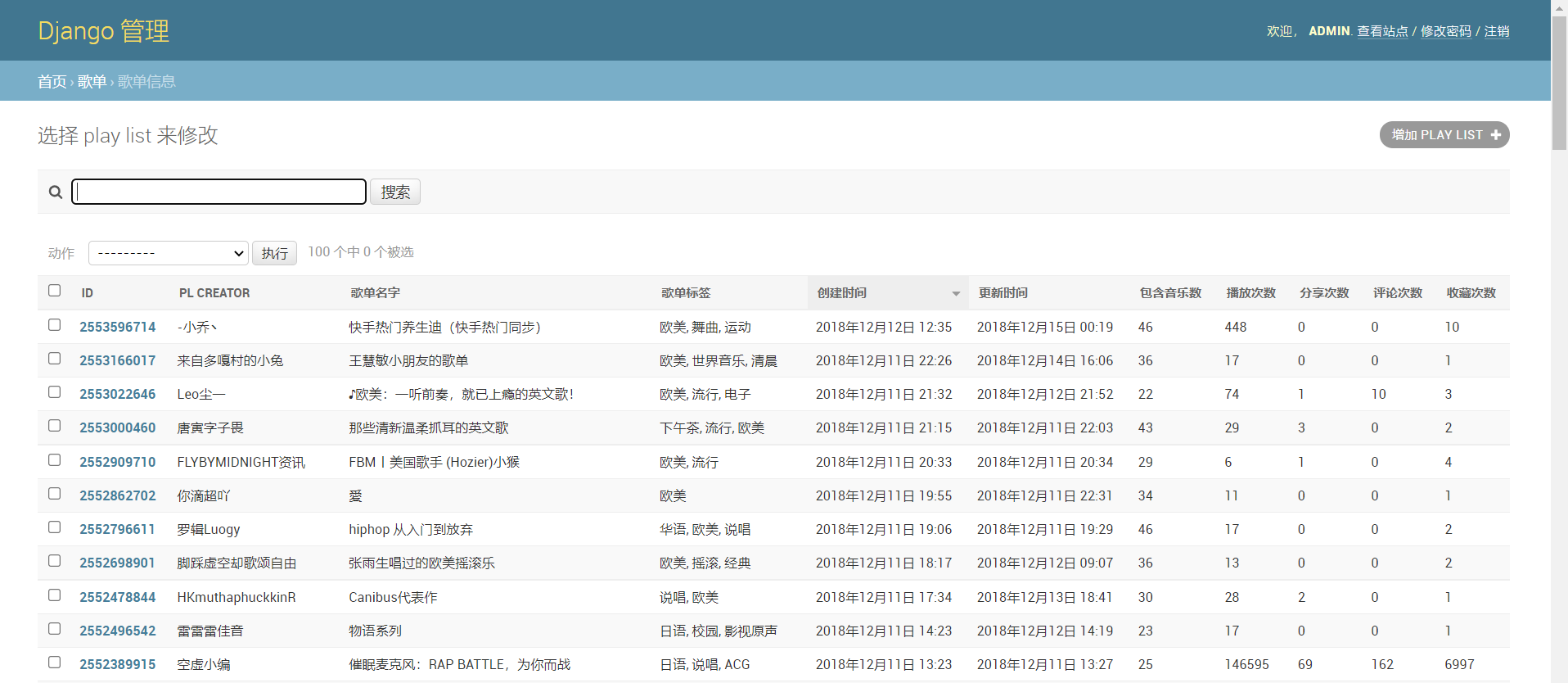
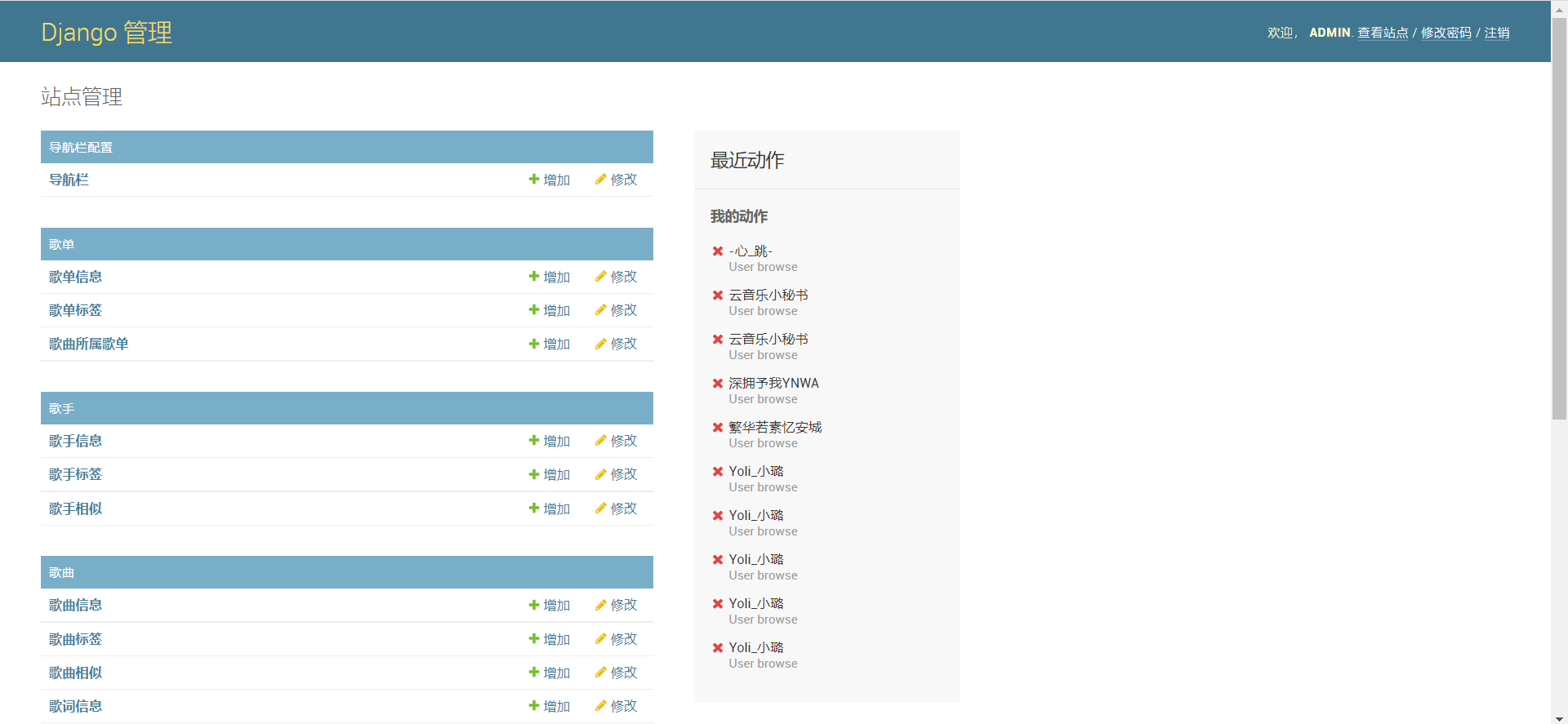
也可以在Django自带的后台管理系统中看到对应的信息(可以自定义展示哪些字段和重命名),如下图:
其他数据的导入方式和歌单信息导入方式一致,完整代码在tomysql/ToMySQL.py
3、设计架构
音乐推荐系统的整体架构设计为:
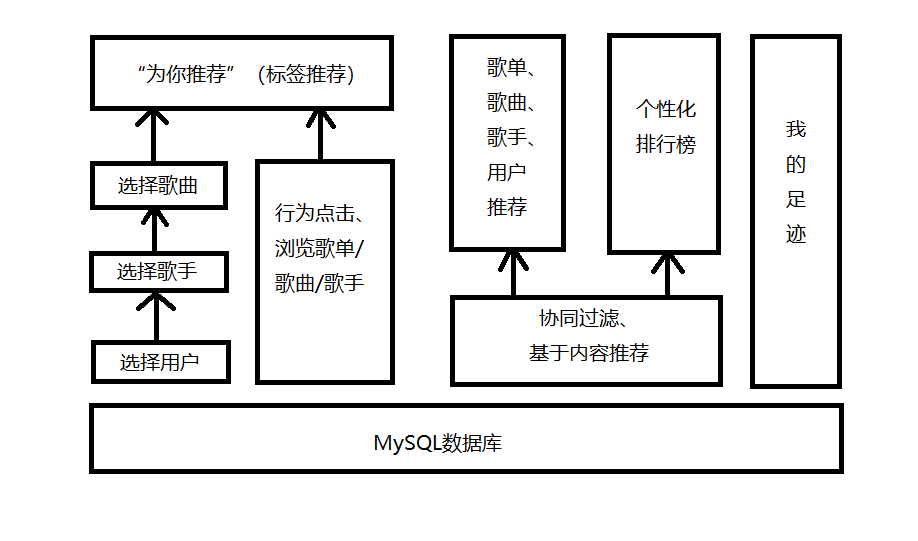
其中的各个模块介绍如下:
MySQL数据库:MySQL存储系统所使用的数据。
选择用户:每次随机从数据库中返回部分用户作为使用系统的用户,这里使用不同的用户是为了区分不同用户在系统中的行为偏好。
选择歌手:用户与系统交互的过程,解决系统的冷启动。当然用户也可以不选择歌手,直接跳过,此时系统中的“为你推荐”的歌手标签部分为热度标签数据。
选择歌曲:用户与系统交互的过程,解决系统的冷启动。当然用户也可以不选择歌曲,直接跳过,此时系统中的“为你推荐”的歌曲标签部分为热度标签数据。
行为点击、浏览歌单/歌曲/歌手:用户在系统中产生的行为记录。用户在浏览某个歌单、歌手、歌曲、用户时,都会基于当前的浏览进行推荐。
为你推荐(标签推荐):基于用户进入系统时的选择和用户在系统中的行为,为用户推荐歌单、歌曲和歌手标签。
协同过滤、基于内容推荐:使用这两种算法计算用户对歌单、歌曲、歌手、用户的喜好程度。
歌单、歌曲、歌手、用户推荐:用户在进入歌单、歌曲、歌手、用户模块时,对用户产生的推荐。
个性化排行榜:基于用户的偏好程度进行排序展示,不同的用户看到的显示界面是不一样的。
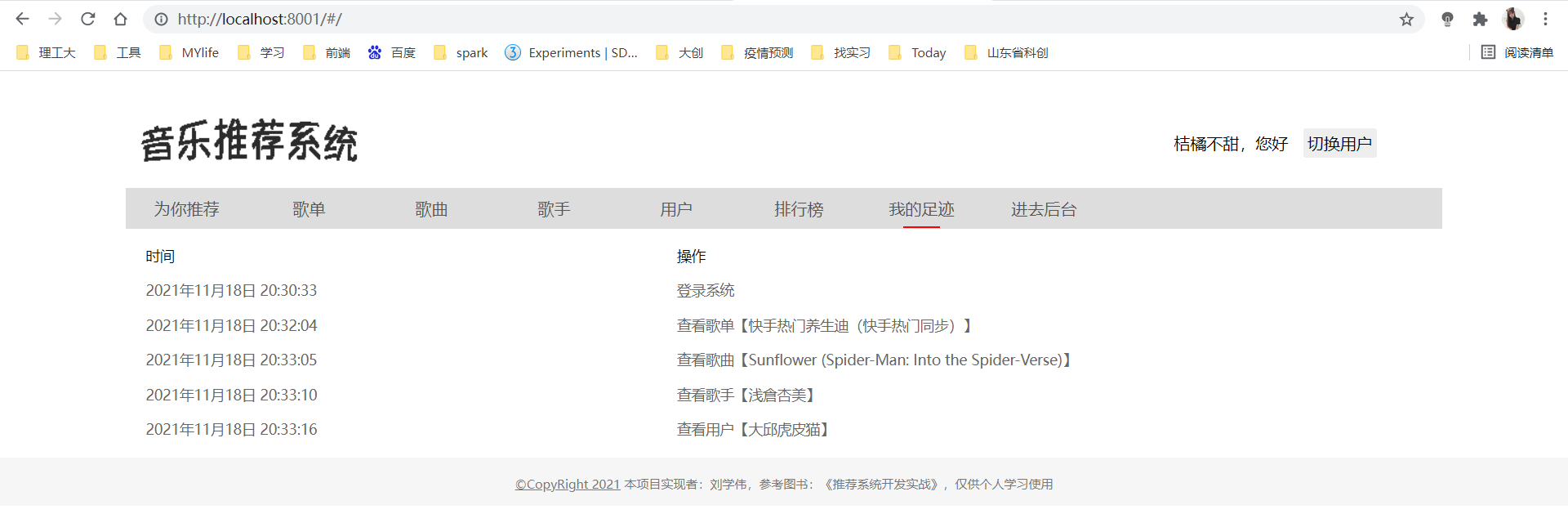
我的足迹:登录系统和在系统内的点击浏览行为的汇总展示。
系统的整体架构设计围绕实现推荐算法来设计,整体设计简单,和真正的推荐系统有很大差距,但实现思路是一致的。
4、实现系统
本系统使用前后端分离的形式开发实现,后端采用Python的Django框架,前端采用Vue框架。
项目实现流程如下图:
4.1、准备环境
1.后端环境准备
后端开发依赖于Python3.7版本,其中使用的包为:Django==2.1,PyMySQL==0.9.0,jieba==0.39,xlrd==1.1.0,gensim==3.6.0。
这些Package名称和对应的版本在目录/z-others/files/requirement.txt文件中,安装时,直接在此目录下执行以下命令即可
pip install -r requirement.txt
2.前端环境准备
前端开发依赖node.js环境,使用的是Vue框架,node.js对应的版本是10.13
4.2、实现后端接口
1.创建项目
选定目录,执行以下命令,创建一个空的Django项目
django-admin.py startproject MusicRec
此时创建了一个空的MusicRec项目,进入该目录,执行以下命令,创建指定的模块。
python manage.py startapp index
python manage.py startapp playlist
python manage.py startapp sing
python manage.py startapp song
python manage.py startapp user
在MusicRec/MusicRec/urls.py中添加对index、playlist、sing、song、user模块的链接,修改后的urls.py为:
from django.contrib import admin
from django.urls import path
from django.conf.urls import include, url
urlpatterns = [
path('admin/', admin.site.urls),
url(r'^index/', include('index.urls'), name='index'),
url(r'^playlist/', include('playlist.urls'), name='playlist'),
url(r'^sing/', include('sing.urls'), name='sing'),
url(r'^song/', include('song.urls'), name='song'),
url(r'^user/', include('user.urls'), name='user'),
]
2.定义数据对象
本实例中定义的数据表较多,包含歌单维度、歌手维度、歌曲维度、用户维度,分别用来存储歌单、歌手、歌曲和用户的相关信息。
例如,歌单信息表的定义如下:
# 歌单信息:歌单ID,创建者ID,名字,创建时间,更新时间,包含音乐数,
# 播放次数,分享次数,评论次数,收藏次数,标签,歌单封面,描述
class PlayList(models.Model):
pl_id = models.CharField(blank=False, max_length=64, verbose_name="ID", unique=True)
pl_creator = models.ForeignKey(User, related_name="创建者信息", on_delete=False)
pl_name = models.CharField(blank=False, max_length=64, verbose_name="歌单名字")
pl_create_time = models.DateTimeField(blank=True, verbose_name="创建时间")
pl_update_time = models.DateTimeField(blank=True, verbose_name="更新时间")
pl_songs_num = models.IntegerField(blank=True,verbose_name="包含音乐数")
pl_listen_num = models.IntegerField(blank=True,verbose_name="播放次数")
pl_share_num = models.IntegerField(blank=True,verbose_name="分享次数")
pl_comment_num = models.IntegerField(blank=True,verbose_name="评论次数")
pl_follow_num = models.IntegerField(blank=True,verbose_name="收藏次数")
pl_tags = models.CharField(blank=True, max_length=1000, verbose_name="歌单标签")
pl_img_url = models.CharField(blank=True, max_length=1000, verbose_name="歌单封面")
pl_desc = models.TextField(blank=True, verbose_name="歌单描述")
# python 2.7中使用的是__unicode__
def __str__(self):
return self.pl_id
class Meta:
db_table = 'playList'
verbose_name_plural = "歌单信息"
其中,verbose_name_plural参数代表该类(该表)在Django后台中显示的中文名
3.API接口开发
这里以前端获取具体歌单信息接口为例,简单介绍开发过程。创建one函数,具体代码如下:
# 获取单个歌单信息
def one(request):
pl_id = request.GET.get("id")
# 信息进行记录
wirteBrowse(user_name=request.GET.get("username"),click_id=pl_id,click_cate="2", user_click_time=getLocalTime(), desc="查看歌单")
one = PlayList.objects.filter(pl_id=pl_id)[0]
return JsonResponse({
"code":1,
"data":[
{
"pl_id":one.pl_id,
"pl_creator": one.pl_creator.u_name,
"pl_name":one.pl_name,
"pl_create_time":one.pl_create_time,
"pl_update_time":one.pl_update_time,
"pl_songs_num": one.pl_songs_num,
"pl_listen_num":one.pl_listen_num,
"pl_share_num":one.pl_share_num,
"pl_comment_num":one.pl_comment_num,
"pl_follow_num":one.pl_follow_num,
"pl_tags": one.pl_tags,
"pl_img_url":one.pl_img_url,
"pl_desc":one.pl_desc,
"pl_rec": getRecBasedOne(pl_id),
"pl_songs": getIncludeSong(pl_id)
}
]
})
最终返回给前端的是一个Json对象。这里使用JsonResponse对字典类型的变量进行格式转换,并返回给前端。
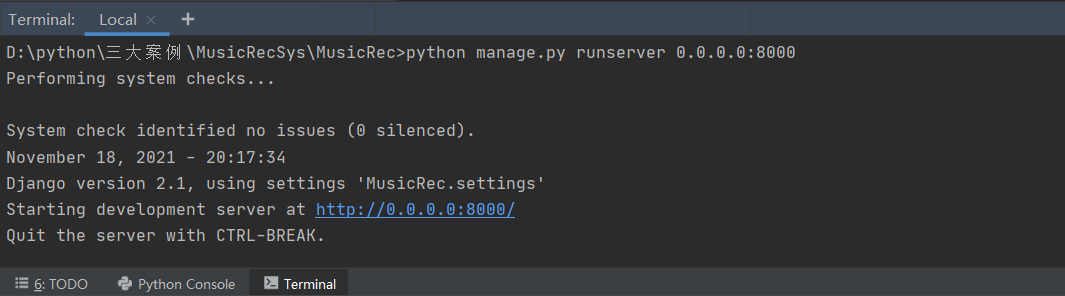
4.启动服务
执行以下命令启动服务:
python manage.py runserver 0.0.0.0:8080
服务启动对应的提示信息为:
4.3、实现前端界面
1.创建项目
前端使用Vue框架实现
(1)安装Vue
npm install vue -g
npm install vue-cli -g
(2)选定用来保存前端项目的文件夹
vue init webpack MusicRec-Vue
(3)进入项目,执行以下命令安装依赖
npm install
2.开发页面
在项目MusicRec-Vue中的src文件夹下建立pages文件夹,创建相关页面
3.启动服务
进入项目文件夹,执行如下命令启动项目
npm run dev

注意:上述命令速度慢或者直接网络连接失败的话,直接安装cnpm环境
安装cnpm
node -v # 查看node是否已安装
npm install -g cnpm -registry=https://registry.npm.taobao.org
cnpm -v # 查看是否安装成功
4.4、系统演示
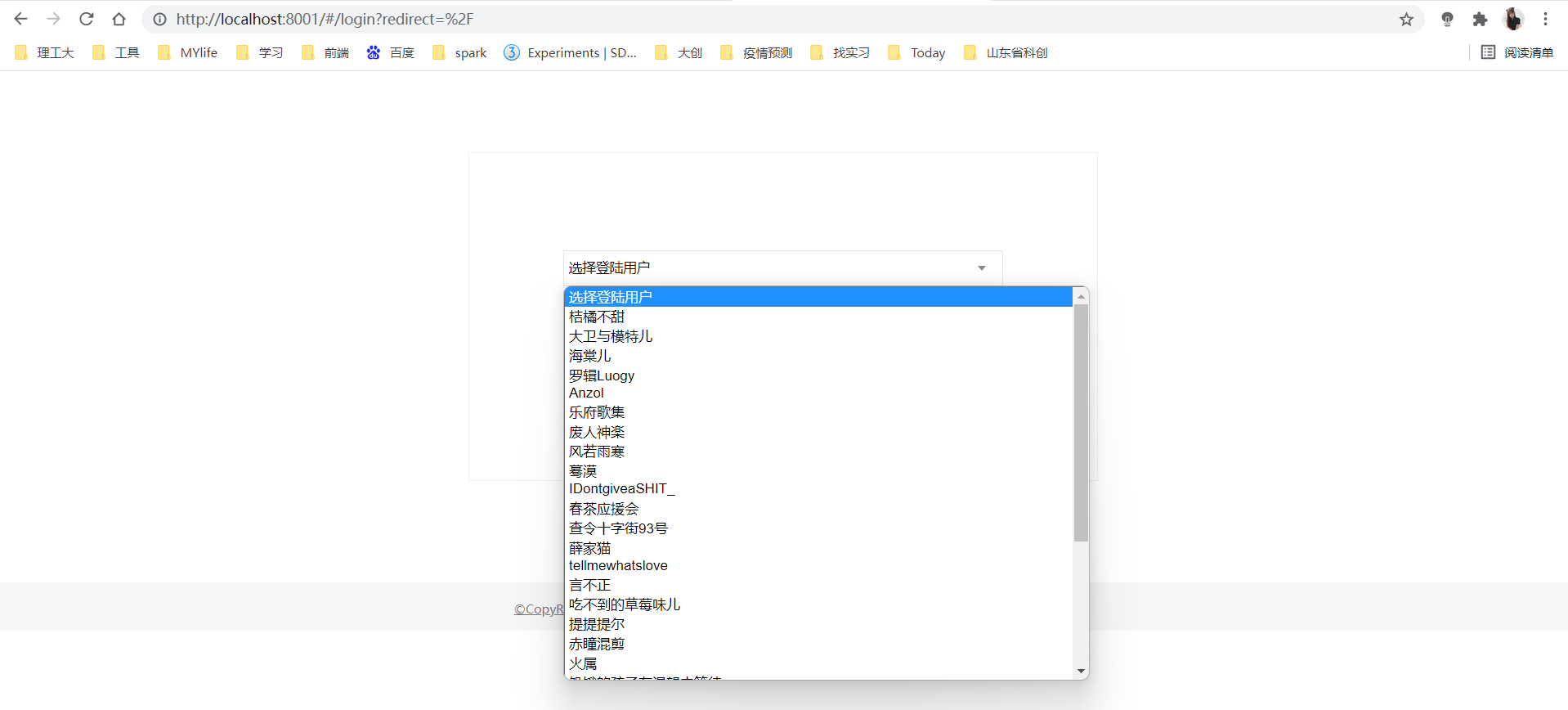
前后端开发完成,下面对主要部分进行演示
1.选择用户
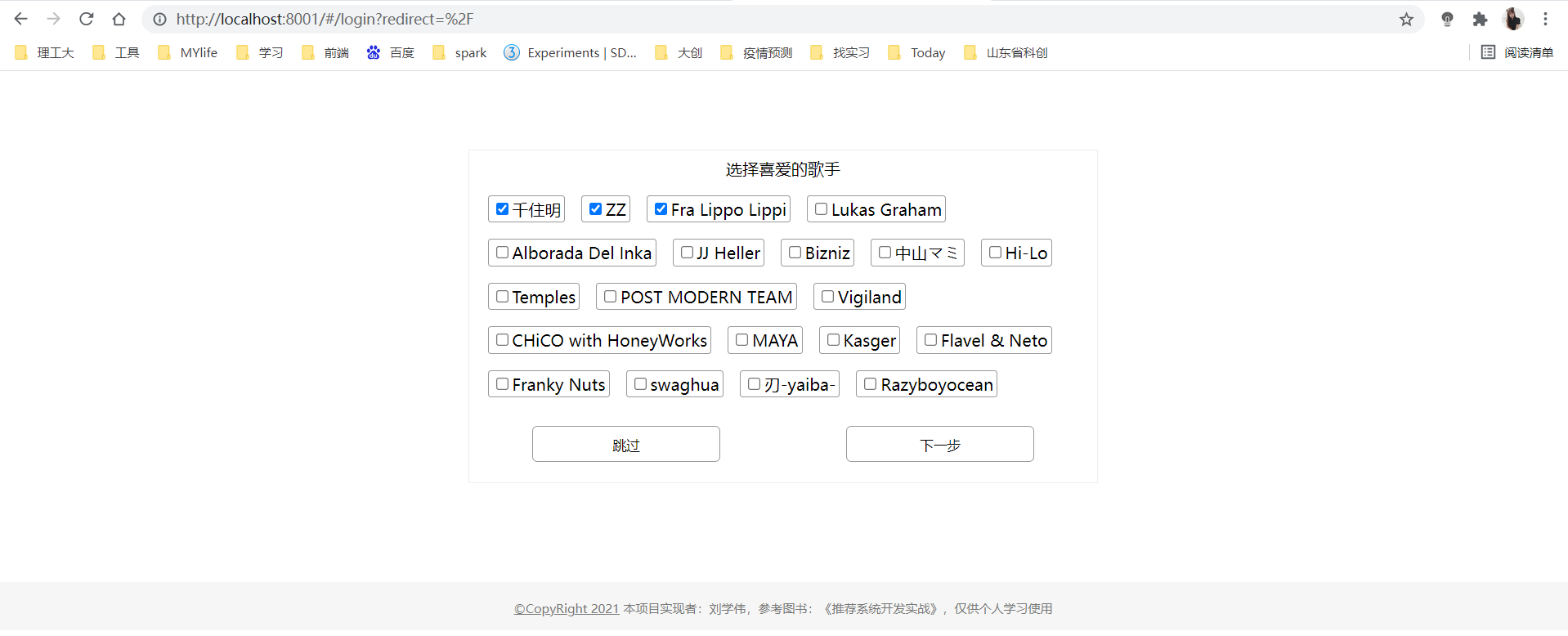
2.选择歌手
3.选择歌曲
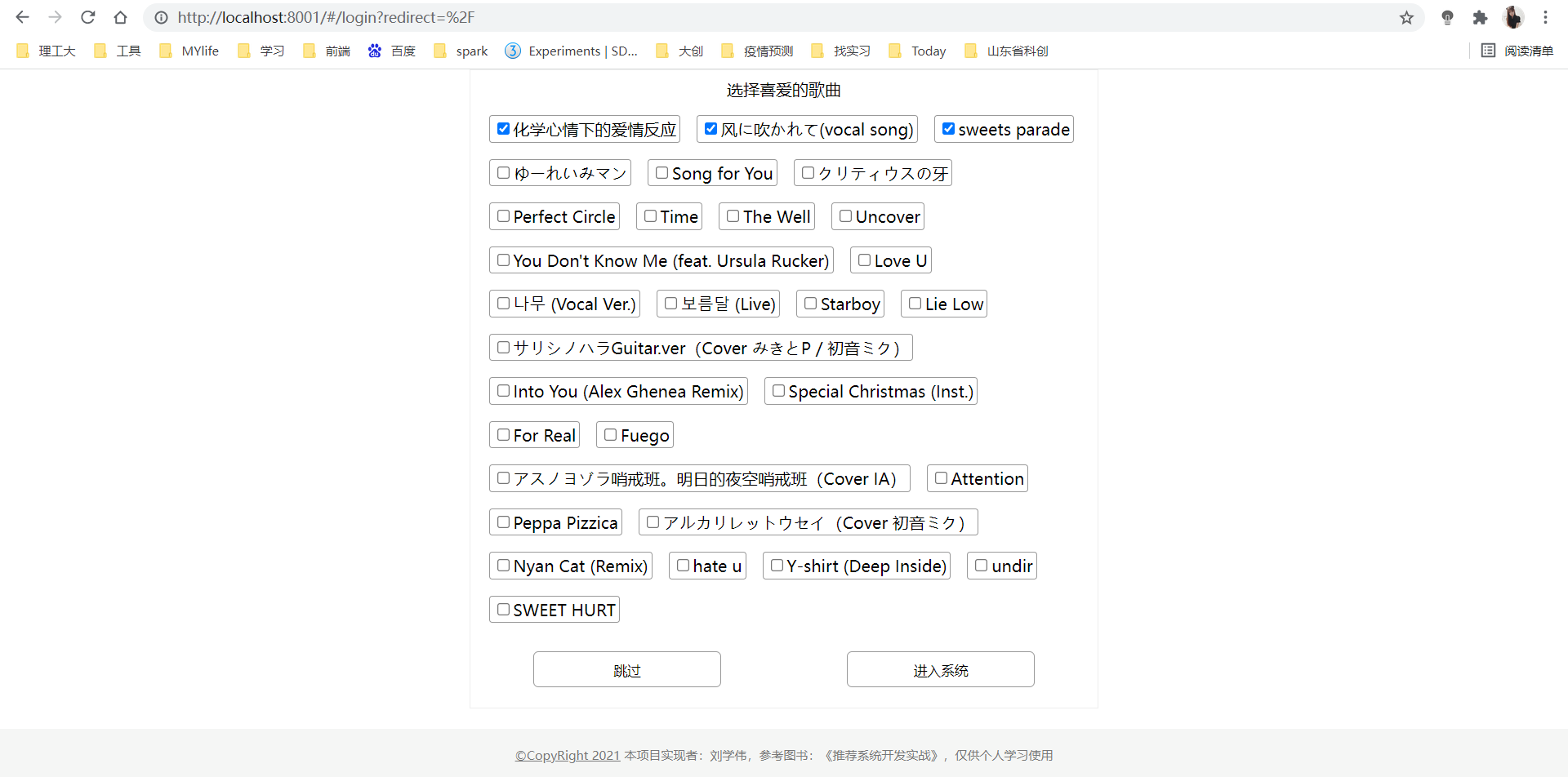
4.“为你推荐”
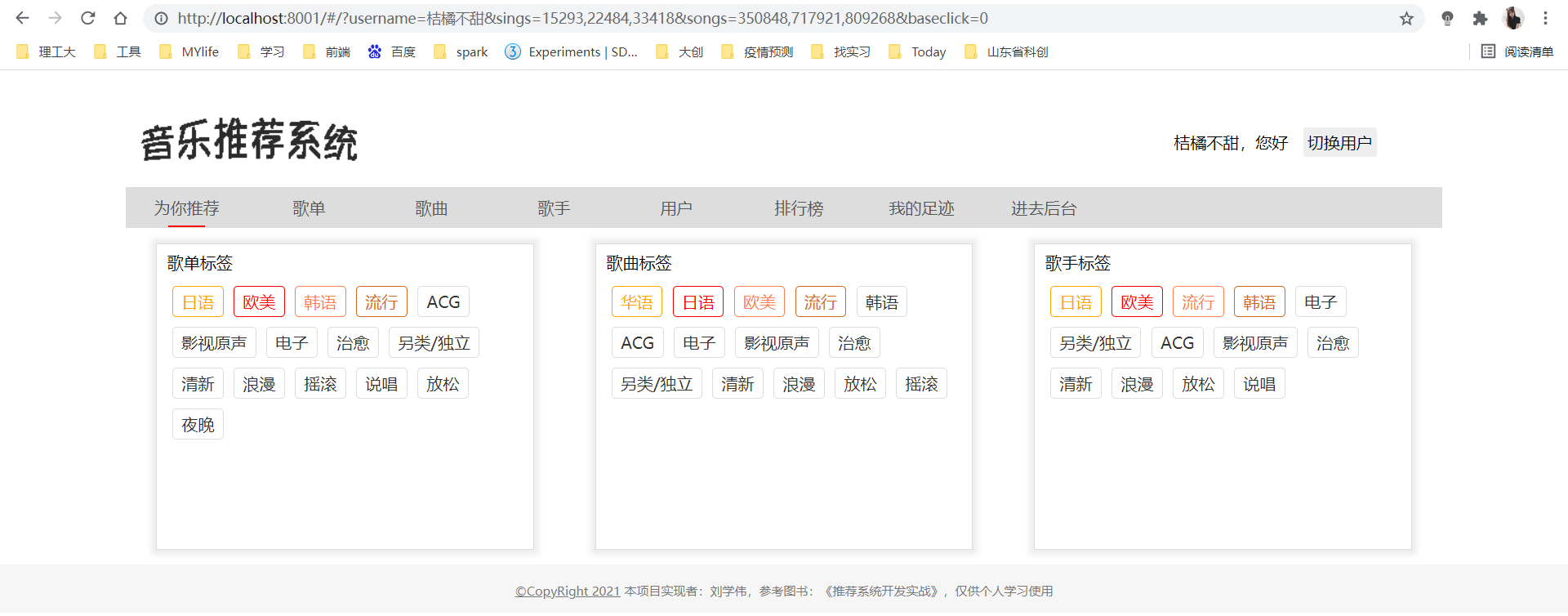
5.歌单与歌单推荐
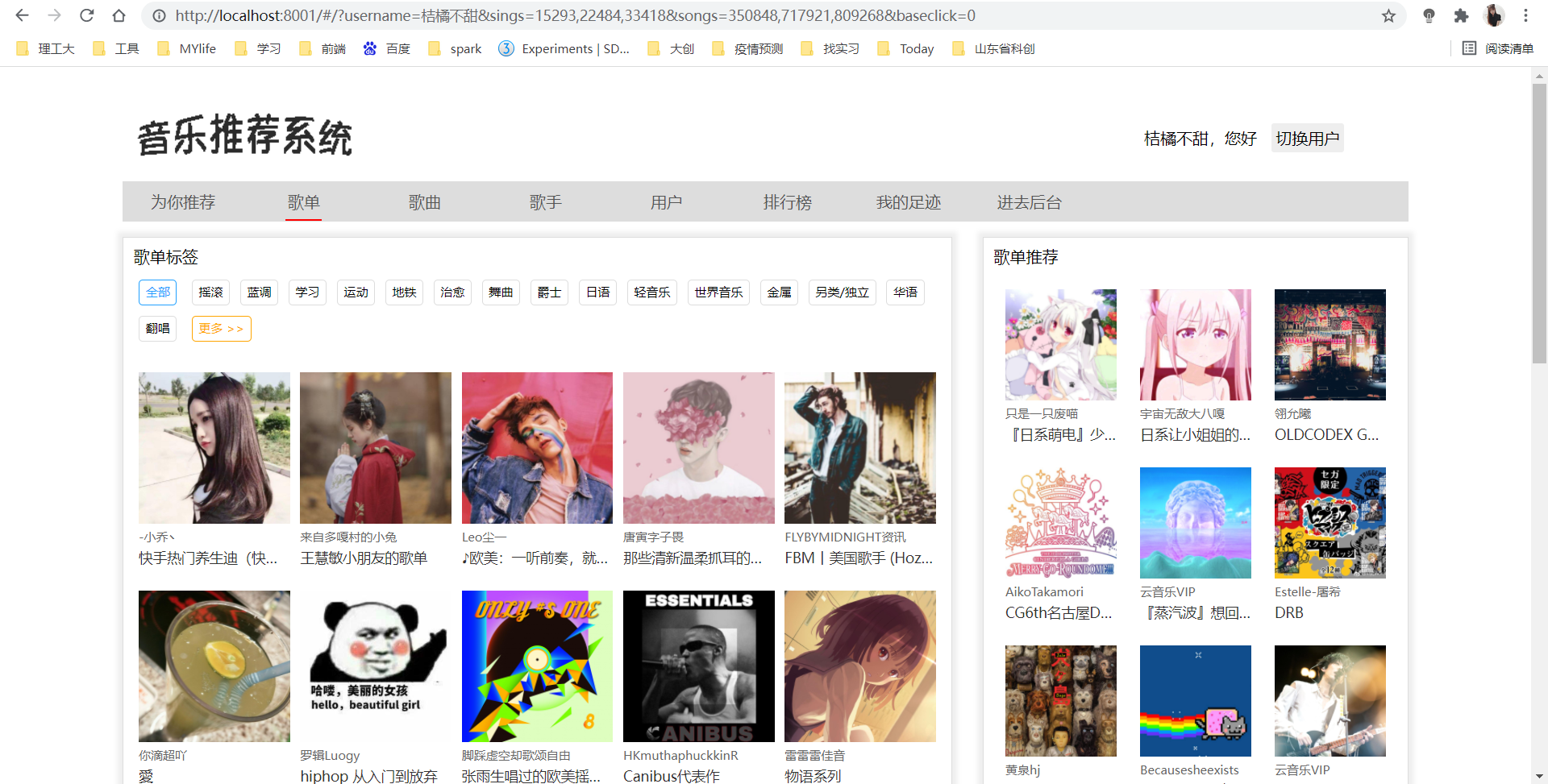
6.歌单详情与歌单详情页推荐
7.排行榜
8.“我的足迹”
9.后台管理
5、把项目部署到阿里云服务器
环境:
5.1、服务器配置
阿里云服务器2核1G内存,centos8版本
5.2、后端环境
、python3.6,其中使用的包为:Django==2.1,PyMySQL==0.9.0,jieba==0.39,xlrd==1.1.0,gensim==3.6.0。这些Package名称和对应的版本在目录/z-others/files/requirement.txt文件中,安装时,直接在此目录下执行以下命令即可Python包和对应的版本
pip install -r requirement.txt
5.3、前端环境
前端依赖nodejs
yum install gcc gcc-c++
wget https://npm.taobao.org/mirrors/node/v10.13.0/node-v10.13.0-linux-x64.tar.gz
tar -xvf node-v10.13.0-linux-x64.tar.gz
mv node-v10.13.0-linux-x64 node
# 配置环境变量
vim /etc/profile
export NODE_HOME=/usr/local/node
export PATH=$NODE_HOME/bin:$PATH
# 刷新配置
source /etc/profile
# 验证
node -v
npm -v
需要安装cnpm
node -v # 查看node是否已安装
npm install -g cnpm -registry=https://registry.npm.taobao.org
cnpm -v # 查看是否安装成功
5.4、数据库环境
linux下的mysql5.7,端口为3306
新建musicrec数据库,将MusicRecSys/MusicRec/z-others/files/musicrec.sql 文件导入
5.5、代码ip配置修改
修改 MusicRecSys/MusicRec/MusicRec/settings.py 文件中的ALLOWED_HOSTS为本地IP地址和本地mysql配置信息
修改 MusicRecSys/MusicRec-Vue/config/index.js 中的 serverUrl
修改 MusicRecSys/MusicRec-Vue/src/assets/js/linkBase.js 中的 serverUrl
5.5、服务器运行项目
进入 MusicRecSys/MusicRec 执行下列命令
# 前台运行
python manage.py runserver 0.0.0.0:8000
# 后台运行
ohup python manage.py runserver 0.0.0.0:8000 >my.log &
进入 MusicRecSys/MusicRec-Vue 执行下列命令
# 安装环境
cnpm install
# 前台运行
cnpm run dev
# 后台运行
nohup cnpm run dev >/dev/null2>&1 &
5.6、访问地址
自此,项目完成部署上线。
项目访问地址为:http://8.136.103.40:8001/
后台管理系统访问地址为(用户名和密码均为admin):http://8.136.103.40:8000/admin/
评论区